GPU Paralellization
THW, Nov 20 2019
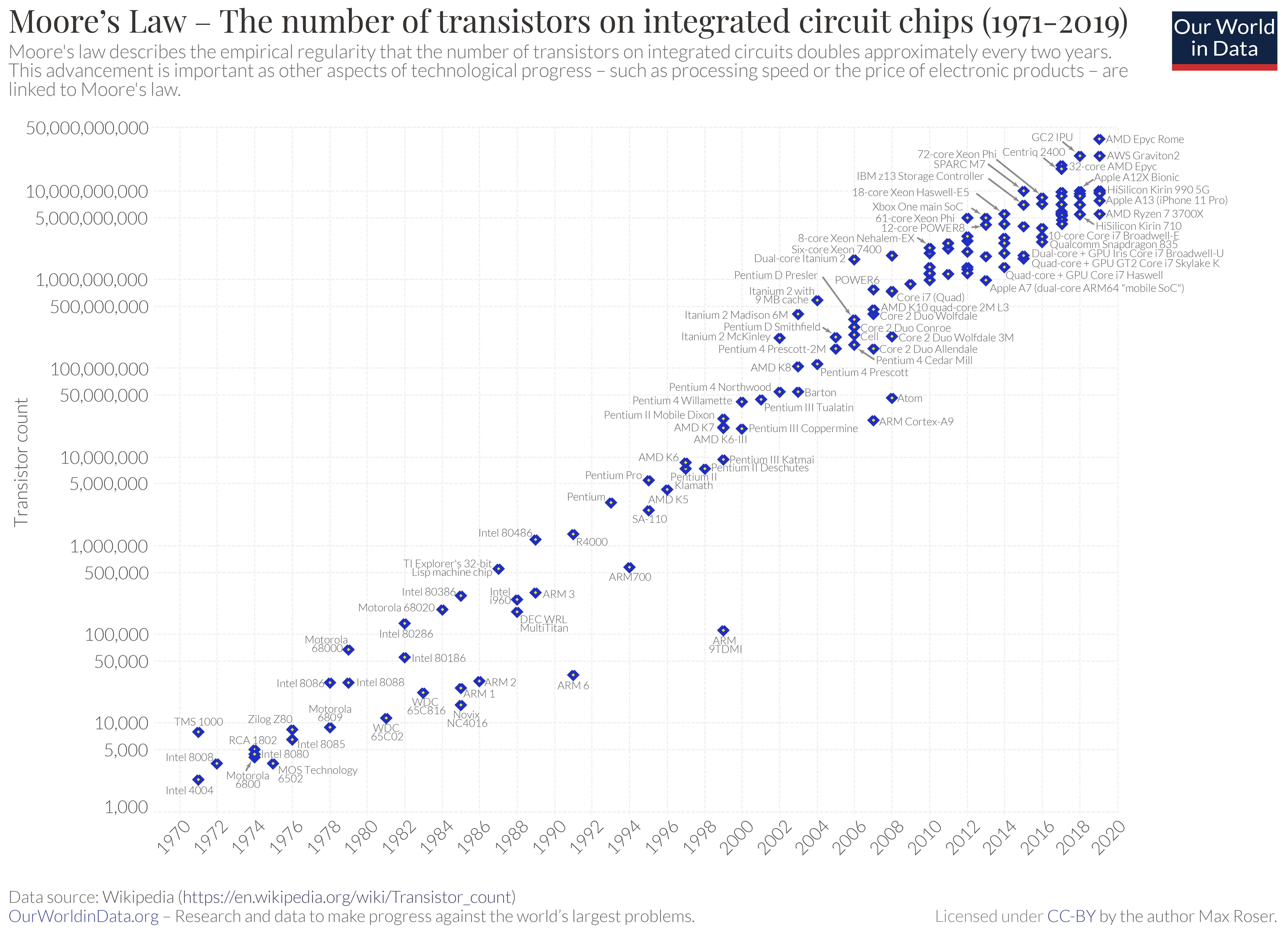
Moore’s Law
{kind=link}
Dennard scaling
- voltage drain, capacitance, inductance \(∝\) transistor size
- clock frequency \(∝ 1 /\) transistor size
- total power is the same!
The end of scaling

CPUs: Latency Oriented
- latency is lag a computer instruction and its completion

- CPUs use all kind of complicated tricks to minimize latency
GPUs: Throughput Oriented
- throughput is number of operations per unit time

- GPUs maximize throughput at the cost of latency
Throughput \(×\) Latency = Queue Size
tasks can be sensitive to latency…
- serial tasks
- sequential or iterative calculations
or throughput
- pleasingly/embarrassingly parallel tasks
- calculations are independent of one another

GPU anatomy
three levels of organization:
- GPUs contain many small “threads” capable of performing calculations
- each thread has a little bit of memory and a
threadIdx(1, 2, or 3D)
- each thread has a little bit of memory and a
- threads are grouped into “blocks”
- each block has some shared memory and a
blockIdx(1, 2, or 3D)
- each block has some shared memory and a
- blocks live on grids


Example: Image Blurring




Shared memory matrix multiply

